
For our final year project (FYP) at university, we fine-tuned pre-trained language models (PLM) for the Sinhala Spell Correction (SSC) task. Our models performed better than the existing solutions in terms of accuracy. One of the main goals of our project was to make our work useful for everyday users. So, we built a simple web app that lets anyone correct spelling mistakes in Sinhala text.
The architecture was pretty much straightforward. We used a two-layered setup: the frontend sends the text to the model, and the model returns the corrected version, which is then shown to the user.
The trickiest part was hosting the PLMs in a way that allowed us to run inference through an API call from the frontend. There are plenty of options for hosting these models, but most of them aren't free, or even affordable. Luckily, Hugging Face Spaces turned out to be a solid option. While GPU-powered machines do cost money, they also offer a free CPU tier, which was barely enough for our needs.
Hosting the PLM on HuggingFace Spaces
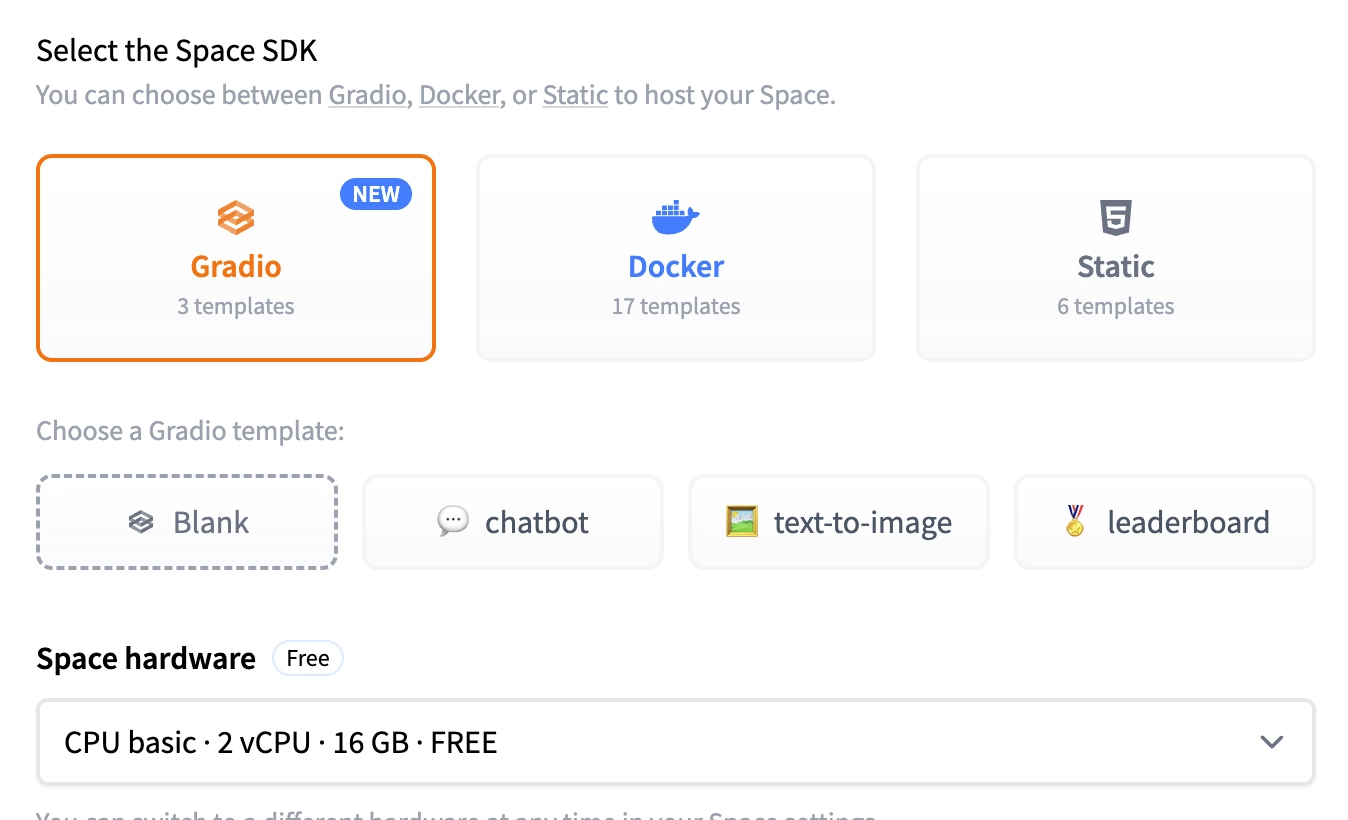
First, create a new space. I selected Gradio as the Space SDK and chose a blank template. Select the Space hardware as CPU basic | 2vCPU | 16GB | Free.
You can start implementing the Gradio app immediately after cloning the HuggingFace repository using the provided link. You can structure your code like below:
1import gradio as gr 2Once you commit your code, it gets automatically deployed to the HuggingFace Space and goes live right away. If your project has any Python dependencies, you can simply list them in a requirements.txt file at the root directory. They will be automatically installed in the environment when the app is deployed.
In our case, we had already uploaded the model checkpoints to Hugging Face, so we simply loaded them directly in the Gradio app. The models don’t need to be public, you can access private models using a HF_TOKEN, which can be securely stored as a secret in your HuggingFace repository.
Inference with the hosted PLM
HuggingFace Spaces provides multiple client libraries (like Python and JavaScript) for handling inference. However, in our case, we had to use Vanilla JavaScript, since the web app was built with legacy PHP.
Below is a sample of the code we used:
1export async function correct(text) { 2With this setup, we were able to host our fine-tuned mT5 model checkpoint for Sinhala Spell Correction and use it to fix errors in sentences submitted through the web app. If you want to host heavier LLMs like Gemma 2 or LLaMA 3.1, you’ll need more powerful machines, which definitely come with a higher cost.
Hope this article is helpful for anyone looking to host PLMs for free or on a budget. You can refer to our code and use our LM Spell web app from the links given below.
If you have any questions or suggestions, feel free to leave a comment.
Comments